Le Troubleshooting, redouté par beaucoup, et mal maitrisé dans la plupart des cas.
Au premier abord il ne s’agit pas d’un sujet des plus intéressants. Pourtant, la pratique du Tshoot est très formatrice.
Confronté à des problèmes très divers, parfois avec un besoin urgent de résolution, il est indispensable de choisir la bonne approche. La manière de procéder est cruciale dans la résolution de l’incident.
Au travers de ce premier article nous aborderons les grandes lignes du Troubleshooting, principalement en réseau.
Les articles suivants seront axés sur la pratique du Tshoot.
1) Généralités
Commençons par les bases : qu’est-ce que le Troubleshooting ?
Le Tshoot consiste à éliminer un ou plusieurs problèmes.
Le processus de recherche se doit d’être réfléchie, intelligent et logique.
Il convient tout d’abord de bien identifier le problème, avant de rechercher sa cause, pour ensuite le résoudre.
Enfin, il est préférable de garder une trace de tout cela.
Le Tshoot peut être nécessaire à toutes les étapes.
A la conception d’un réseau, il est possible de rencontrer un comportement inattendu.
Dans ce cas-là, l’urgence est rarement forte.
En revanche, sur un réseau en production, un incident va nécessiter un Troubleshooting rapide et efficace.
Mais alors comment être bon en Troubleshooting ?
Premièrement, il est indispensable de maitriser les configurations mises en place. Autant sur la partie théorique que pratique.
Il est difficile et risqué de débugger une infrastructure ou des technologies que l’on ne maitrise pas.
Donc avant de vouloir débugger, il faut savoir configurer.
Une fois la théorie et la pratique maitrisées, il faut apprendre les techniques de Tshoot.
En Tshoot le choix de la bonne approche est crucial.
Nous verrons qu’il y a plusieurs approches possibles, chacune avec leurs avantages et leurs inconvénients.
Deuxièmement, il y a des bonnes pratiques à connaitre.
Ces dernières permettrons souvent d’éviter les problèmes, et au pire rendront le Tshoot plus simple.
Etant donné qu’il y a souvent un facteur « urgence », faciliter le travail en amont ne peut être que bénéfique.
2) Maintenances
Une maintenance bien effectuée permet souvent d’éviter le Troubleshooting.
Un bon travail en amont est nécessaire, mais cela en vaut la peine.
En informatique il existe plusieurs modèles connus pour la maintenance.
L’un des plus utilisés est ITIL – IT Infrastructure Library.
Il s’agit d’une référence en termes de bonnes pratiques à mettre en place dans un service informatique.
Les objectifs sont les suivants :
- Que le service IT réponde au mieux aux attentes
- Proposer une bonne qualité de service informatique aux employés
- Améliorer en continu le service IT
- Réduction des coûts
- Améliorer la disponibilité du service IT
- Etc…
ITIL permet de s’assurer que le service IT est toujours aligné avec les besoins.
Cela entraine aussi une complexification du service IT.
Voici rapidement quelques termes intéressants, notamment présents en ITIL :
- SLA – Service Level Agreement: Définition de la qualité de service attendue du prestataire par le client (temps de disponibilité du service, performances)
- Service : Délivre une valeur à un employé, afin de faciliter la réalisation de son travail
- Service management : Aligner les services avec les besoins des employés. Il faut suivre le service et rester à l’écoute des utilisateurs.
- Utilisateur : Celui qui utilise le service
- Service provider : Celui qui fournit le service
- Processus : Un ensemble d’activités, dans le but de produire un résultat
- Asset : Atout en français, il permet de travailler, et de générer de la valeur (BDD, serveur, etc…)
- Availability Management : S’assurer que le service est disponible et couvre tous les besoins
- Baseline : Mesure du fonctionnement normal d’un service, d’une application, d’un équipement, du réseau… A comparer avec une baseline précédente ou future
- Workaround : Limiter l’impact de l’incident, quand une solution n’est pas encore disponible
- Know Error Database : Liste d’erreurs connues, et comment les résoudre
En termes de modèle, il existe aussi FCAPS – Fault Configuration Accounting Performance Securiy.
Il s’agit d’un Framework de gestion d’un réseau informatique créé par l’organisation international de standardisation (ISO).
Il est divisé en 5 catégories :
- Fault Management: Détection et résolution des problèmes, prévention des nouveaux incidents, conservation de traces sur les résolutions
- Configuration Management: Sauvegarde de configurations et de données relatives aux configurations (documentation), rédaction de procédures de configuration, programmation des changements
- Accounting Management: Collecte de statistiques sur l’utilisation (par chacun) des services informatiques
- Performence Management: Maximisation et maintien des performances. Monitoring du réseau
- Security Management: Maintien de la sécurité du réseau (intrusion, perte de données, piratage, contrôle des permissions, authentification, etc…).
Le Cisco Lifecycle Services Approach est un modèle à suivre pour le déploiement de matériel (Cisco) dans un réseau.
Les phases sont les suivantes :
- Prepare : Définition des besoins
- Plan : Définitions des assets nécessaires pour répondre au besoin
- Design Implement : Elaboration d’une solution répondant aux besoins
- Operate : Maintien du bon fonctionnement du réseau au jour le jour
- Optimisation : Optimisation et amélioration de la solution
Le CLSA promet d’augmenter les profits, la productivité, la satisfaction des clients, etc…
Dans tous ces modèles nous retrouvons globalement les mêmes idées.
Libre à chacun de choisir ou non l’un de ces modèles.
Dans tous les cas, il est important d’appliquer les idées avancées dans les modèles précédemment cités.
3) TSHOOT Structuré vs Non-Structuré
En Troubleshooting, le plus sage, et généralement le plus efficace est de réaliser du TSHOOT structuré.
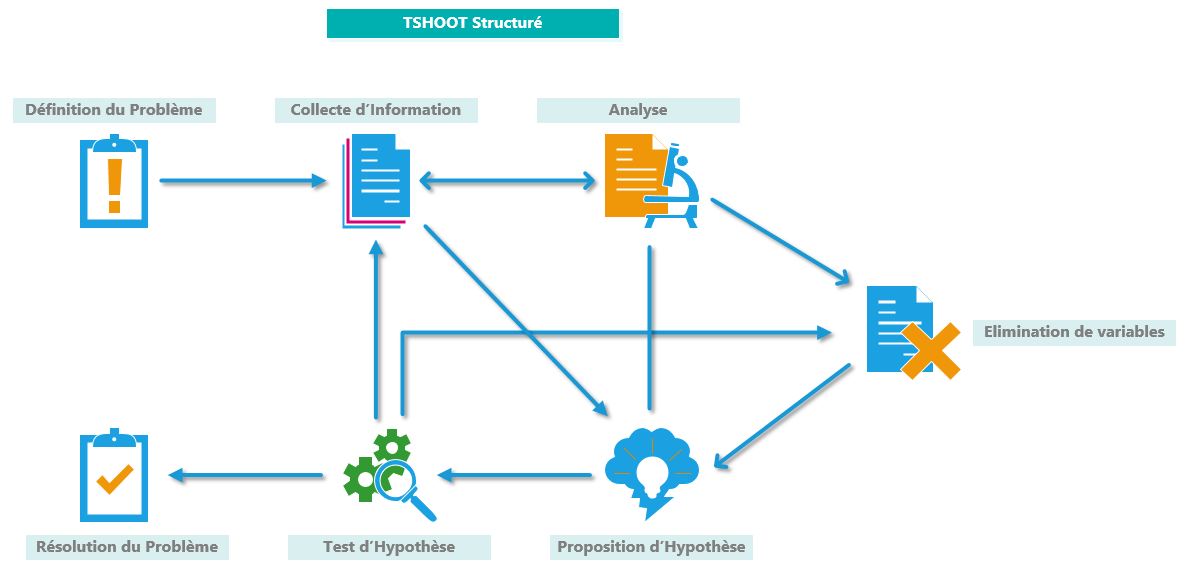
La première étape est de définir le problème. Qu’est ce qui ne fonctionne pas correctement ?
Une fois le problème clairement défini, il convient de collecter un maximum d’information.
Attention, il faut collecter suffisamment d’information, mais pas trop non-plus.
Certaines infos ne sont pas nécessaires, mieux vaut se concentrer sur celles qui sont utiles.
Il s’agit là d’un point très important. Avec les bonnes informations, le TSHOOT est beaucoup plus facile. Une collecte de données trop rapide rend en général le TSHOOT plus difficile.
Ensuite, il faut analyser les données collectées.
C’est ici qu’une bonne connaissance des notions théoriques et pratiques est indispensable.
Au fil de cette analyse, il sera possible d’éliminer des variables.
Au bout d’un temps, il sera possible de proposer une hypothèse.
Si cette hypothèse semble recevable, il sera possible de la tester.
Attention tout de même à ne pas aggraver le problème initial. L’idéal est d’avoir un plan pour revenir en arrière.
Il y a alors plusieurs suites possibles.
Soit le problème est résolu, soit il ne l’est pas.
Si il ne l’est pas, peut-être a-t ‘il évolué. En tout cas, il faudra suivre ce processus plusieurs fois, jusqu’à résolution.
Une autre méthode, est de réaliser ce que l’on appelle du Shoot From The Hip.
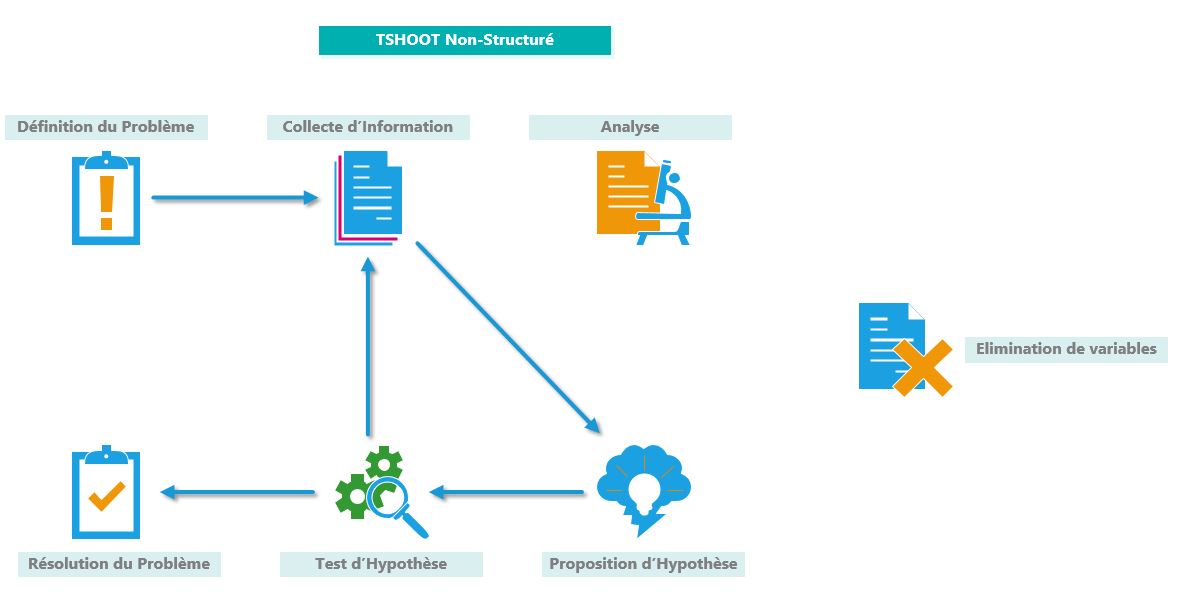
Cette méthode est considérée comme du TSHOOT non-structuré.
Souvent la collecte d’information n’est pas complète, et l’analyse trop rapide voire inexistante.
Des solutions sont alors testées un peu au hasard.
Les chances de résolutions faibles, et cela peut déboucher sur une aggravation du problème initial.
Présenté comme ceci, le SFTH ne parait pas être une bonne idée.
Pourtant, il est pratiqué par beaucoup.
Souvent, face à un problème, nous cherchons à le résoudre le plus rapidement possible (surtout si il y a urgence).
La collecte d’information est donc trop légère. Le désire de résolution rapide mène à une analyse rapide.
Sur des problèmes simples cela fonctionne relativement bien.
Sur des problèmes plus complexes, cette méthode est à déconseiller.
Même si cela peut paraitre plus fastidieux, il est préférable de recourir au TSHOOT structuré.
4) Les approches de Troubleshooting
Lors-ce que vous faites face à un incident, il est importent de choisir la bonne approche, afin de faciliter la résolution.
Il existe diverses approches, mais aucune n’est la meilleure dans tous les cas.
Il est donc important de connaitre ces approches, afin de choisir la meilleure selon la situation.
Top Down
L’approche Top Down consiste à commencer le TSHOOT par la couche applicative du modèle OSI.
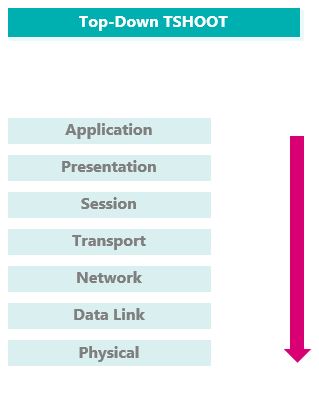
Etant donné que chaque couche du modèle OSI est dépendante de celle du dessous, il est possible d’assumer que si la couche actuelle fonctionne, celles du dessous fonctionnent aussi.
En effet, la couche Application ne peut pas fonctionner, si la connectivité au niveau Network n’est pas opérationnelle.
L’idée est donc de partir de la couche Application, tout en sachant que le plus souvent le problème vient de cette couche.
Il faut ensuite trouver la couche la plus haute qui est fonctionnelle.
L’inconvénient est qu’il faut avoir accès aux couches les plus hautes, ce qui n’est pas toujours le cas.
Cette méthode est donc conseillée si vous suspectez que le problème provient du niveau 7, et que vous avez accès à la partie applicative.
Bottom-Up
L’approche Bottom-Up consiste à commencer le TSHOOT par la couche physique du modèle OSI.
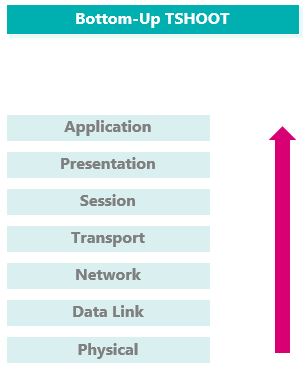
Procéder à des vérifications au niveau 1 peut être simple et rapide aux emplacements proches, mais peut se révéler fastidieux à réaliser sur la totalité d’un grand réseau.
Sur les grands réseaux, l’idée est de commencer par réduire le rayon de recherche.
Divide And Conquer
L’approche Divide-And-Conquer consiste à commencer le TSHOOT au milieu du modèle OSI, souvent au niveau 3.
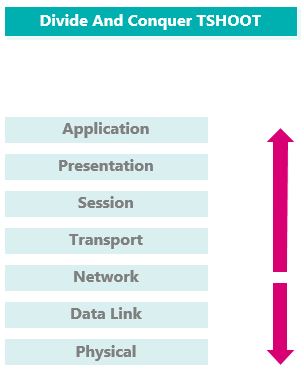
En fonction du résultat des tests, il faudra monter ou descendre dans le modèle OSI.
Par exemple, si les tests au niveau 3 sont concluants, nous pourrons assumer que les niveaux 1 et 2 sont aussi fonctionnels.
En général, cette approche est la plus efficace.
Follow The Path
Ici le but est de suivre le chemin, depuis l’appareil rencontrant un problème, et ce jusqu’à la cible.
Ce processus peut être utilisé aux différentes couches du modèle OSI.
Une fois le problème localisé, il sera possible de le résoudre.
Par exemple, un PC ne peut plus accéder au serveur FTP.
Premièrement, nous pouvons vérifier la connectivité au réseau local.
Ensuite, nous pouvons vérifier la connectivité avec la passerelle.
Nous pouvons poursuivre en testant la connectivité avec tous les équipements intermédiaires.
Et ensuite, est-ce que le PC peut accéder au serveur (d’une autre manière qu’en FTP).
En général, le plus simple est de commencer par un Traceroute.
Sopt The Diffrences
L’idée de cette approche est de définir ce qui a changé depuis la dernière fois où le problème n’était pas présent.
Une bonne documentation des changements peut être d’une grande aide.
Une sauvegarde régulière et un historique des configurations aident aussi à la recherche.
Il est aussi possible de comparer deux équipements fonctionnant ensemble.
Leur configuration devrait être similaire. En les mettant côte à côte, l’analyse est simple et rapide.
Move The Probleme
Ici l’idée est de déplacer l’équipement suspecté, et de voir si le problème se déplace aussi.
Par exemple, si un PC n’a pas accès au réseau, il faut utiliser le câble Ethernet d’un poste fonctionnel.
5) Bonnes pratiques
Terminons par parler des bonnes pratiques en réseau, qui vous éviteront bien des problèmes, et vous aideront pour le TSHOOT.
Documentation
Premièrement, il est très important de documenter le réseau.
La documentation doit être faite en même temps que l’implémentation.
Elle doit aussi évoluer au fil des modifications.
Plus la documentation sera détaillée, mieux ce sera.
Nous pouvons y retrouver :
- Des schémas du réseau (avec plan de câblage exact)
- Un détail de ce qui a été mis en place
- Des explications sur le fonctionnement
- Les configurations avec des explications
- Des guides de configuration et de modification
- Une liste des choses à vérifier en cas de TSHOOT
- La liste des mots de passe stocké de manière sûre (chiffrée)
Trop souvent la documentation est négligée, voir absente.
Cela finit toujours par poser problème.
Connaissance du réseau
Ce point parait évident, mais la connaissance du réseau que l’on administre/TSHOOT est indispensable.
Si vous avez à votre charge un nouveau réseau, il faut apprendre à le connaitre.
Si vous devez faire du TSHOOT sur un réseau que vous ne connaissez pas, avant toute chose, renseignez-vous sur celui-ci.
C’est ici que la documentation joue un rôle très important.
Sauvegarde
Une fois le réseau dans un état stable, réalisez des sauvegardes des configurations des équipements.
Il est conseillé de conserver les anciennes sauvegardes.
Dans l’idéal, il faudrait que les sauvegardes se fassent automatiquement à intervalle régulier.
Sinon, il faut les faire à la main.
Même si la configuration n’est pas censée avoir été modifiée, mieux vaut réaliser tout de même une sauvegarde. En effet, il est possible que quelqu’un ait fait des changements.
L’idéal serait de rédiger une procédure (même succincte) de restauration des configurations.
Quant aux données, il est évident qu’elles doivent aussi être sauvegardées.
Cohérence
Un point plus difficile à définir, garder un réseau cohérent.
Au fur et à mesure du développement du réseau, il faut que celui-ci garde sa cohérence.
Chaque ajout doit rester dans l’esprit de ce qui a déjà été fait.
De préférence, minimiser le nombre de constructeur différents.
Cela rendra le réseau bien plus simple à administrer.
Monitoring
Le monitoring est très appréciable lors-ce qu’il est mis en place.
L’idée ici est de pouvoir consulter l’état du réseau à partir d’une interface.
Il est aussi possible de recevoir des alertes en cas de problème.
Parmi les choses qu’il est possible de monitorer :
- Charge des liens réseau
- Charge CPU
- Charge RAM
- Occupation disque
- Températures des équipements / composants
- Trafic WEB
- Nombre de connexions VPN actives
- Connectivité avec un équipement / un service (ex : page WEB)
- Etc…
Bien entendu, ces informations sont gardées en mémoire.
Il est alors possible de consulter l’état du réseau à un moment donné.
A l’aide du monitoring il est possible de réaliser une Baseline
Baseline
La baseline est une « capture » de l’état du réseau à un instant T.
La baseline doit être réalisée lors-ce que le réseau est dans un état stable.
Il est ensuite possible de refaire une baseline, et de la comparer à l’ancienne.
Procédure en cas de panne
Avoir une procédure en cas de panne peut faire gagner beaucoup de temps.
L’idée est de prévoir les pannes qui peuvent survenir, et de définir les actions à entreprendre pour la résolution.
Par exemple, si le switch 3 tombe en panne :
- Vérifier la présence de la documentation, du schéma réseau, du plan de câblage du switch
- Retirer l’ancien switch
- Placer le nouveau
- Récupérer la sauvegarde de la configuration de l’ancien switch
- L’importer dans le nouveau
- Vérifier la configuration (définir les tâches pour la vérification)
- Câbler le nouveau switch
- Tester le bon fonctionnement
- Mettre à jour la documentation si besoin
Une fois les procédures rédigées, l’idéal serait de simuler une panne, et de procéder à la résolution.
Cela permet de s’entrainer et de mettre à l’épreuve la procédure.
Avoir du SPARE
En cas de panne matériel, il faudra remplacer l’équipement en panne.
Il est rarement possible de déporter les fonctionnalités sur un autre équipement
S’il n’est pas possible d’attendre le remplacement de l’équipement en panne (achat, garantie), il faut avoir un équipement de secours.
C’est ce que l’on appelle le SPARE.
Cela induit bien évidement un coût, car il faudra acheter un équipement supplémentaire, et il ne sera pas utilisé tant qu’il n’y a pas de panne.
Pour limiter les coûts, il est possible d’acheter un équipement de secours moins performant.
Au pire, il faut conserver un ancien équipement.
Garder les systèmes à jour
En informatique il est conseillé de toujours garder les systèmes à jour.
Cela permet de corriger des bugs, améliorer la stabilité et les performances, corriger des failles de sécurité, ajouter des fonctionnalités, etc…
Attention tout de même, il peut arriver que les MAJ comportent des bugs.
Si l’environnement est crucial, il est recommandé d’appliquer la MAJ dans un environnement de test avant de l’appliquer dans l’environnement de production.
Historique du TSHOOT
Autre bonne pratique, conserver un historique des problèmes rencontrés, et la procédure de résolution.
Cela pourra aider à résoudre les problèmes suivants plus rapidement, ou au pire à éliminer des possibilités.
De plus, cet historique pourra être partagé / transmis avec d’autres personnes.
Phases de maintenance
Lors-ce qu’il est nécessaire d’agir sur un réseau en production, l’idéal est de le faire dans les heures creuses, et d’annoncer une période de perturbation.
Si la disponibilité du réseau est critique, il est risqué d’agir en dehors des périodes de maintenance.
Protection physique
Finissons par parler de la protection physique des équipements.
Placer les équipements dans des lieux sûrs est vivement conseillé.
Cela signifie que seules les personnes autorisées doivent y avoir accès.
De plus, ces lieux ne doivent pas comporter de risque (inondation, température trop élevées ou trop faible, perturbation électromagnétiques, etc…).
Autre chose importante, la protection contre les surtensions.
Un réseau électrique n’est pas parfait, et des surtensions peuvent mettre à mal les appareils (surtout en cas d’orage).
L’utilisation d’onduleurs est vivement conseillée.
De plus, en cas de coupure de courant, les équipements resteront allumés.
Aussi, certains appareils comportent deux alimentations.
Il est alors possible de les relier à deux réseaux électriques déférents.
Merci pour cette introduction très intéressante.